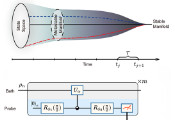
一个机器学习问题需要多少个量子比特?
要使一种机器学习范式具有普适性,它必须拥有通用逼近特性——即能够以任意精度逼近任意目标函数。在变分量子机器学习中,可学习函数类同时取决于数据编码方案和模型可优化部分的结构。该工作证明,最新提出的比特-比特编码方案能高效构建性地实现通用逼近特性。更重要的是,该团队揭示了这种结构可计算解决特定数据集学习问题所需量子比特数,从而建立了首个变分量子机器学习资源估算框架。 应用比特-比特编码对OpenML多个中型数据集测试发现,平均仅需20个量子比特即可完成编码。该研究还扩展出可处理超大规模数据集批处理的新编码方案,并成功应用于十亿级转录组Tahoe-100M数据集——实验表明其所需编码量子比特数已超越经典模拟能力上限。值得注意的是,研究发现所需量子比特数并不总是随数据集特征维度增加,在某些情况下反而可能减少。
量科快讯
【中国移动申请的一项量子比特映射方法发明专利进入公示阶段】国家知识产权局最近公示的信息显示,中移(苏州)软件技术有限公司与中国移动通信集团有限公司联合申请了一项名为“量子比特映射方法、装置、设备、介…
5 小时前
5 小时前
10 小时前
10 小时前
11 小时前
【安恒信息申请一项基于量子密钥的数据安全传输技术发明专利】据国家知识产权局最近公示信息,杭州安恒信息技术股份有限公司申请了一项名为“基于量子密钥的数据安全传输方法、装置、设备及介质”的发明专利(申请…
1 天前
【中国移动申请一种基于量子迁移的遥感图像识别方法发明专利】据国家知识产权局近日公示的信息,中移(苏州)软件技术有限公司与中国移动通信集团有限公司联合申请的发明专利“基于量子迁移的遥感图像识别方法、系…
1 天前
【AQT的囚禁离子量子计算机现已在亚马逊Braket上架】欧洲领先的量子计算机提供商AQT日前宣布,其离子阱量子计算机IBEX Q1现已通过亚马逊云服务(AWS)上线,从而为全球用户提供了云端访问欧…
1 天前
1 天前