无损模式扇入解决高效光子卷积运算
近日,华中科技大学张新亮、董建绩教授团队成功开发了一种高效光子卷积器,该技术通过模式复用扇入解决了片上光信号合并时的损耗问题。相关研究成果发表在《Nature Communications》上,题目为 Highly Efficient Photonic Convolver via Lossless Mode-Division Fan-In 。
扇入问题:从“单道合流”到“立体通行”
在光子集成芯片中,扇入(Fan-in)是指将多路计算结果汇聚相加,是光学计算中常见操作之一。传统的单模扇入(single-mode fan-in,SFI)可类比为把多条车道强行并入一条单车道:所有通路的光信号必须挤进单模波导,光学互易机制导致模式不匹配与耦合损耗,造成显著信号衰减,从而限制系统级联规模(图1a)。
为解决这一问题,华中科技大学研究团队提出了一种无损的多模模式扇入(Multi-mode fan-in,MFI)解决方案,其核心思想是在同一波导内利用若干相互正交的空间模式,为每一路输入分配“专属车道”,即不同的正交模式,从而实现无损合并。形象地说,这相当于在微尺度上修建了一座“光子立交桥”:不同信号在各自模式通道中并行传输,避免了传统单模合并时的能量衰减。实验结果显示:传统单模扇入损耗约为3.53 dB,而多模扇入在三模式情况下的平均损耗均低于 0.4 dB,接近无损合并水平。
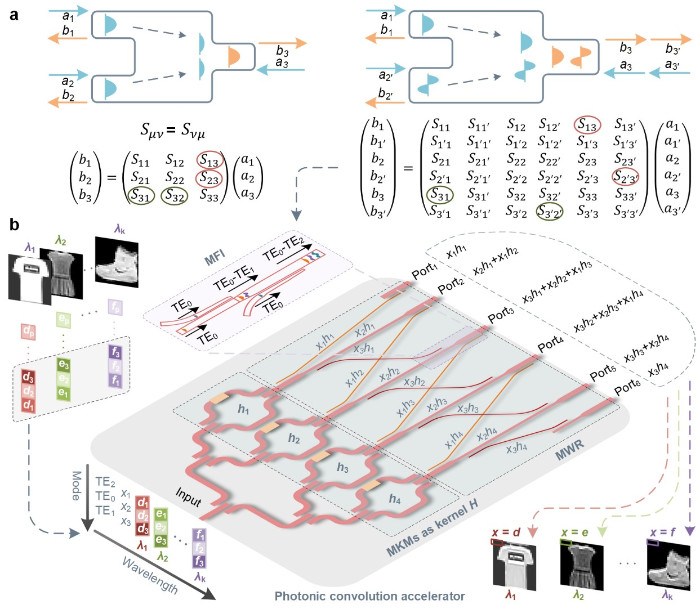
将概念变为器件:米粒大小的光子卷积加速器
在解决模式扇入损耗问题后,研究团队进一步实现了一颗高度集成的光子卷积加速器芯片,完成了从物理概念到功能器件的验证。不同于传统依赖时间–波长交织(Xingyuan Yu, et al., Nature 589, 44-51, 2021)或波长–空间交织(Shiji Zhang, et al., Nanophotonics 13, 19-28, 2024)方案,该工作首次提出并实现了模式–空间交织的卷积架构,将空间模式作为独立计算维度,实现了可兼容并行波长维度的卷积操作。首先,输入向量并行加载到 M = 3 个正交空间模式,经多模 3-dB 耦合器分路后,信号扇出为4路,进入 N = 4 个多模核调制器(multimode kernel modulator, MKM)进行权重加载,即卷积核加载;随后通过多模波导路由(multimode waveguide routing, MWR)完成卷积滑窗操作,同一波导不同模式的求和由多模光电探测端口完成(即多模扇入),避免了单模耦合损耗。
该结构可并行处理 K个波长,单周期完成 K×M×N 次乘加(MAC)运算;滑窗操作通过光路自然传播实现,几乎不消耗额外功率。通过逆向设计,所有功能集成于面积仅约 0.42 mm²(不足米粒大小)的芯片上,计算精度约 6–7位。在 MNIST 手写数字识别任务中,该器件光域准确率达 95.2%,仅比电域低0.6%,理论计算密度可达 125.14 TOPS/mm²(每秒万亿次操作/平方毫米)。相比传统方案,该模式–空间卷积显著提升了吞吐率和能效,为片上大规模光子卷积及高密度光子互连提供了可扩展路径。
意义与展望
该研究提出的无损多模扇入方案,突破了片上光计算的信号合并损耗瓶颈,使卷积等核心算子在模式维度实现了高效、近乎无损的累加。结合模式–空间卷积架构,系统在同一芯片内完成空间滑窗,且兼容波分复用并行运算,显著提升了计算密度和能效比,为下一代低功耗、高吞吐率的人工智能(AI)硬件开辟了全新路径。
该项工作得到国家自然科学基金项目资助;博士研究生孙尚森与张世纪为论文共同第一作者,华中科技大学董建绩教授为通讯作者。








